Hi @olemarius,
I’ll add one additional caveat to @Jan_Wienold’s, witch is that the substitution used by dcglare is in the contrast term, not in the brightness term of the DGP equation.
I’m not an expert in BREEM, but I think what Jan is saying is that in cases without shading devices, a direct view to the sun is the main cause of glare, and evaluation of the contrast term may be unnecessary. That said, there doesn’t seem to be a widely accepted metric for evaluating indoor view-to-sun glare (except perhaps for ASE), and BREEM seems to require use of the DGP equation, regardless. (And, I would argue, dcglare does use this equation, so it meets the criterion that you’ve laid out.)
As to fair competition, all of the methods we are discussing are free (both gratis and libre), so anyone complaining that their competitor is using a more advantageous method is free to use that method as well. That said, I’m not sure why a manufacturer would be using these methods. Just like with UGR and electric lighting, the glare score of a product in a lab has little relation to the glare experienced in a real use case. What manufacturers should insist is that designers use consistent methodology when comparing products.
What I’m curious about, @Jan_Wienold, is if Ev and DGPs aren’t accurate enough to predict glare occurrence in simulation, then do you think DGP is accurate enough? If we’re talking about photographs, where the luminance field is known with certainty, then sure, we can use DGP to assign a glare category, but rendered images just don’t have sufficient accuracy for this. Unfortunately, both your paper and mine use DGP as a baseline for comparison instead of survey data, which is fine for academic discussion, but doesn’t answer whether the results are accurate enough for real use. Saying that DGP is 100% accurate compared to itself isn’t that impressive…
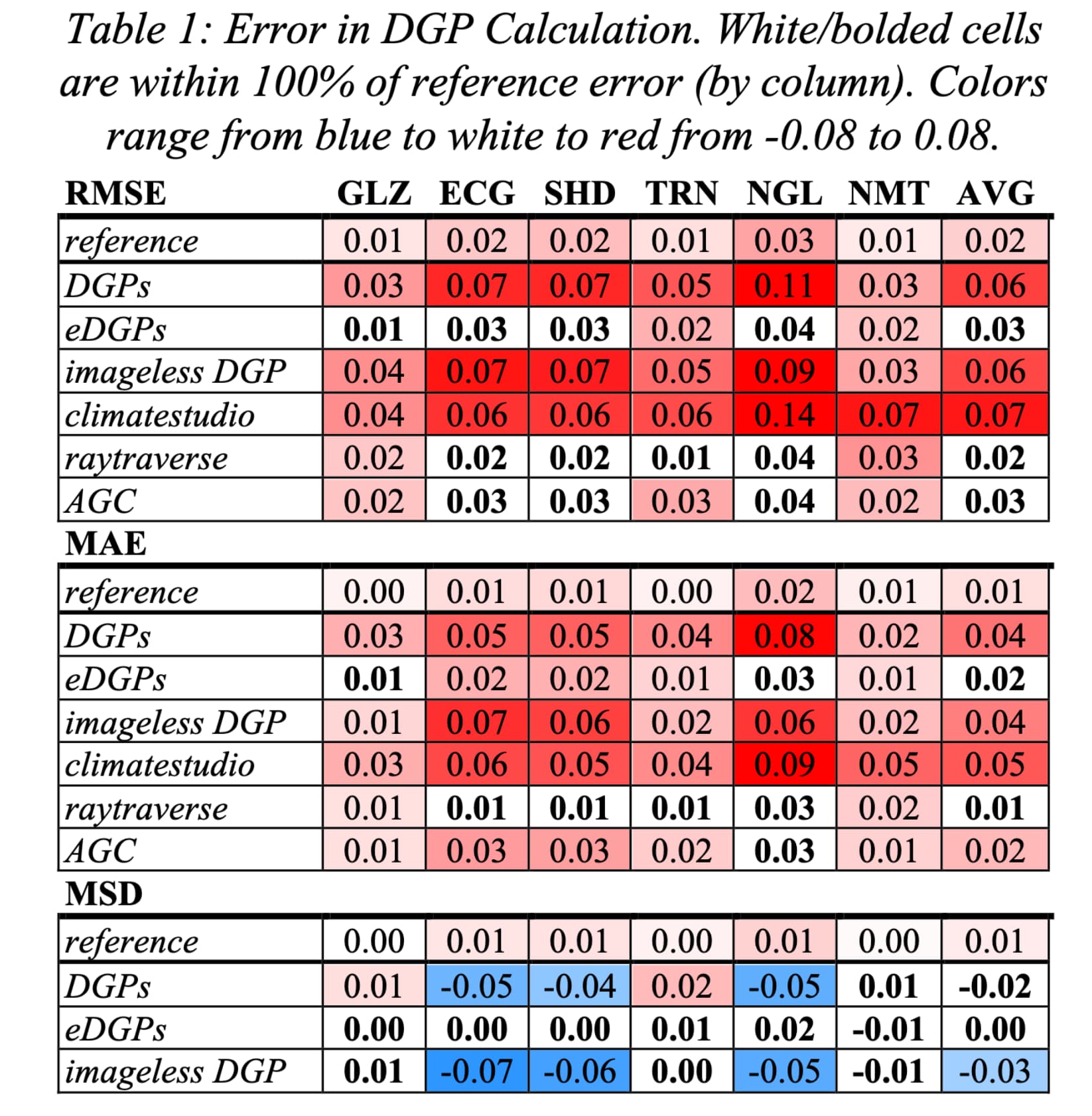
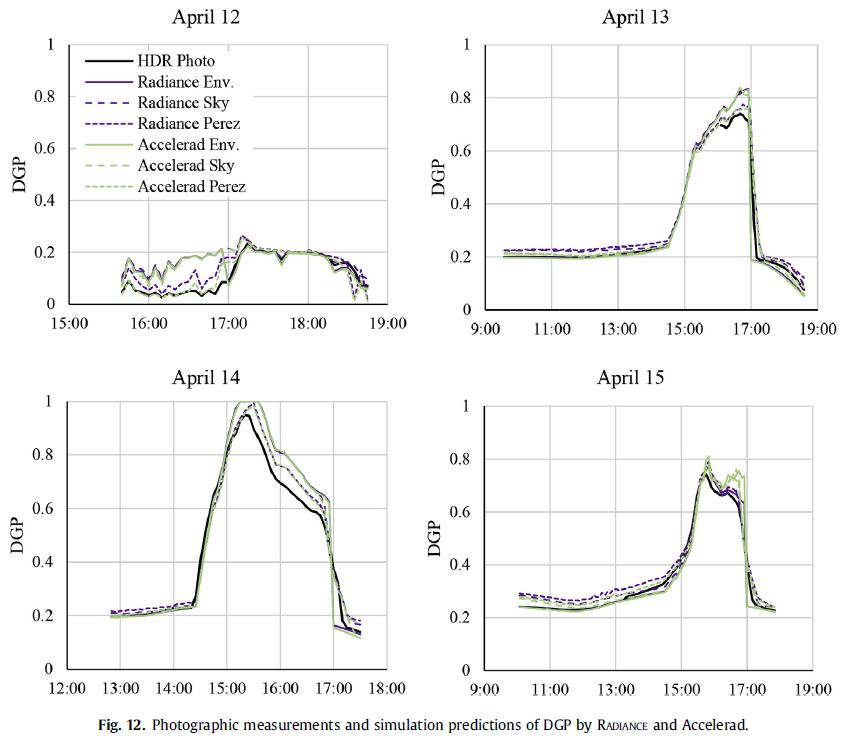
@J_Alstan_Jakubiec found in a long-term study that DGP can misidentify the glare category by two categories, with what appears (from my reading of the figures) to be a bias for being too high. My field work comparing HDR photography to several different simulation methods found that when DGP is near the transitional 35-45% range, it’s not uncommon for simulations to be off by 5%.
Keep in mind that I was using expensive equipment to precisely measure material reflectance and sky conditions. In predictive simulation, that information is not available, which will result in larger errors. Even using a database of measured values like spectraldb, a search for “white paint” results in a reflectance range of 30%, which is certainly enough to throw off DGP calculations. A thread on the accuracy of Radiance simulations lists a number of validation studies, through which I’ve found that typical expectations of Radiance are that it produces results within 20% of measured illuminance values. An error of 20% in Ev is enough to reduce DGP from 45% (intolerable) to 39% (perceptible). Again, these studies mostly used measured reflectance values. For simulations using LM-83 recommended Lambertian reflectance values (20% for floors, 50% for walls, 70% for ceilings), the error is probably greater, and those are the “90% of models” that I referred to earlier.
So that is your choice between plague or cholera (which is my new favorite metaphor). None of these methods are certain, but each is useful in some cases. Standards like BREEM are problematic because they set specific targets, where your results will be influenced mainly by the accuracy of your representation of materials, and also to some extent by your choice of algorithm. In my opinion, the best you can do is to make sure you follow the wording of the standard. This is why I prefer simulation to be used for comparisons, and why I emphasize the limitation of dcglare for specular surfaces (because with the right settings, dcglare can still help you rank the relative glare risk of open-weave shades and EC glazing, but it will not correctly rank different specular materials). Of course, I also contend that standards should require reporting of simulation error margins, so as you can see, no one is listening to me anyway  .
.