I just started using radiance and I think this is a very basic question.
I am exploring the relationship between -ad, -ab, -as, -aa, -ar and computational accuracy and computational load in order to find the appropriate parameter settings for lighting designers to simulate.
As a test model, we assume a simple building of 5m10m2.8m with only one window on the south side, and set the observation point at (2.5,5,0.7).
I set the above parameters appropriately, and tried to get a trend by looking at the number and location of sample points using lookamb.
At first, when I set ad = 2, ab = 1, which is a very small number of sample points, I assumed that the ray from the observation point would hit the surface of the room at 2^2 = 4 points, and that the information from 4 sample points would be output.
However, when ar=2, aa=0.5, the number of sample points was more than 4, about 8.
I assume this is due to the IC being done and the cache points being added.
In response to these, here are my questions.
[Q1]
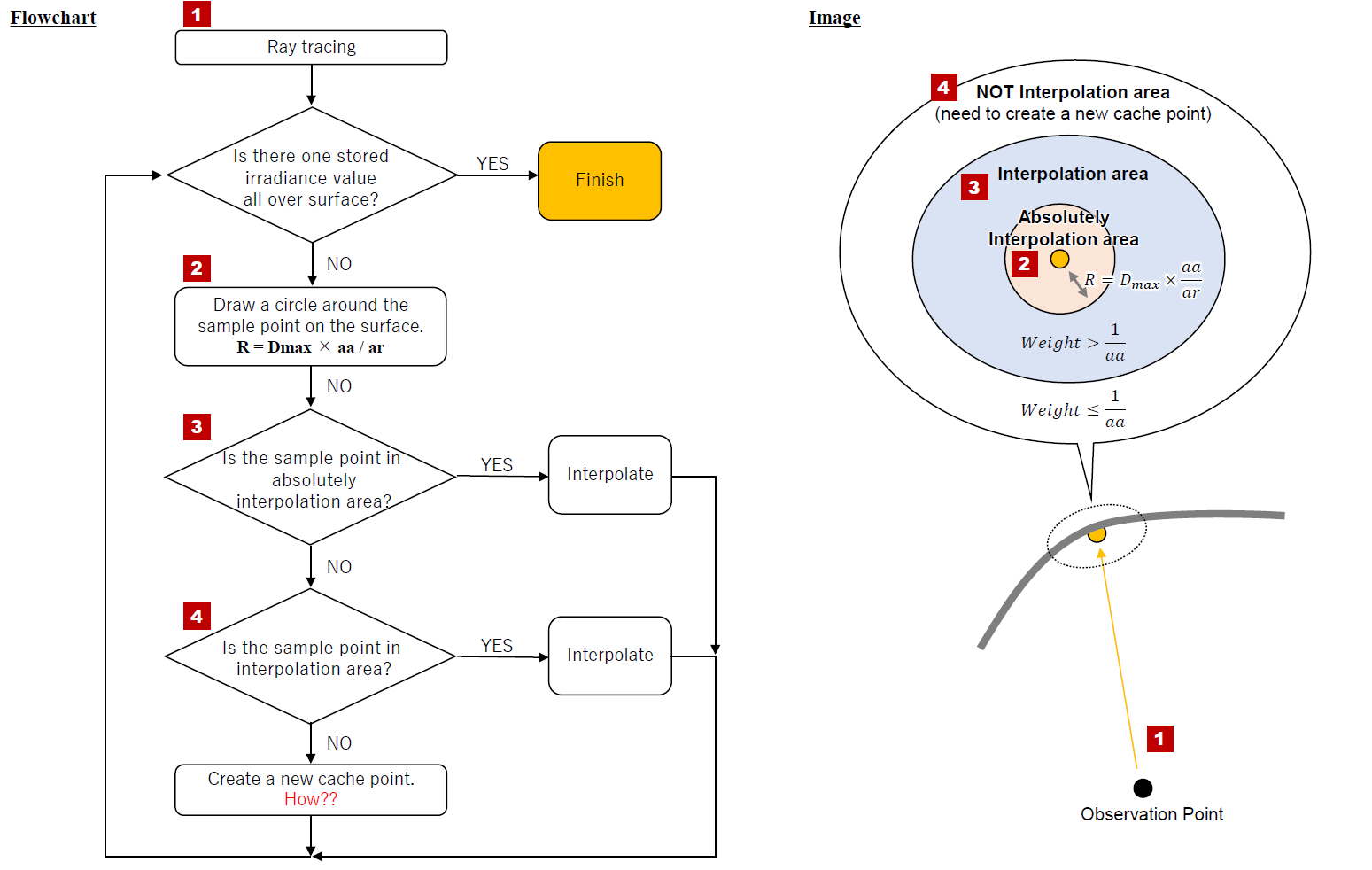
What is the calculation algorithm for the ray being fired and the cache point being determined?
Here is a flowchart of what I am assuming. Is this correct? I’m sure it’s more complicated than that.
Q2.
When adding a new cache point by IC, how do you determine its position?
Q3]
What kind of algorithm is used for super sampling (-as)?
I imagine dividing the hemisphere that fires the ray into patches, and sending new rays between patches with large changes in brightness.
The interreflection calculation is one of the most evolved parts of Radiance, and fairly complex as a result. The -ad and -as settings roughly control the initial samples for the first bounce, but the -ad setting is adjusted as needed to evenly divide a hemisphere.
[Q1]
What is the calculation algorithm for the ray being fired and the cache point being determined?
Here is a flowchart of what I am assuming. Is this correct? I’m sure it’s more complicated than that.
The first sample position (2.5, 5, 0.7) in your case causes the hemisphere of incident interreflections to be sampled, using at least 49 rays, which is the minimum if -aa > 0.
I did not see your flowchart. The code in rt/src/ambcomp.c is the ultimate reference.
[Q2]
When adding a new cache point by IC, how do you determine its position?
It is based on the accuracy estimate of nearby cached values, which depends on many things, including the Hessian calculation that determines indirect lighting gradients.
[Q3]
What kind of algorithm is used for super sampling (-as)?
I imagine dividing the hemisphere that fires the ray into patches, and sending new rays between patches with large changes in brightness.
Yes, it is something like that. Samples are added to hemisphere subdivisions based on stratified sampling and local variance estimates.
[Q4].
What is the u-vector output by lookamb?
This is a vector in the surface plane pointing in the direction of the maximum or minimum position gradient. (I don’t remember which.)
The genambpos.pl script in ray/src/util is a great way to visualize cache values, although it is not properly documented.
Hi, Greg.
It was a question half a year ago, but I didn’t understand it after all, so I will ask again.
How did the 49 rays calculate the number?
I tried to read the code in rt / src / ambcomp.c, but it was too difficult for me.
It would be greatly appreciated if you could tell me the specific location of the paper or code that would be helpful.
7 is the minimum size in each dimension, leading to 49 samples (or so) as the lower limit for values that will be included in the irradiance cache. Anything smaller than this would yield such a crude approximation that there would be little sense in storing it. This is my logic, but the number 7 is not magic. It could have been 6 or even 9.
② I presume that the user-defined parameter ad and minadiv are calculated and compared in the code below to determine which one to use.
However, even after reading the code, I still couldn’t understand it.
What are the expressions on lines 262 and 265 of the code?
Line 262 is used for -aa 0 calculations to keep the number of hemisphere samples from exceeding that allowed by the -lw setting. Line 265 makes sure i is 1 with -aa 0 and MINADIV (7) otherwise. The smaller of i and the n calculated on line 264 is used.
③ Does this mean that even if ad = 2 etc. is set, the value of ad will actually increase from the calculation result of ②?
Yes, if -aa > 0, indicating that you want irradiance caching to actually work. Sending out two diffuse ray samples and expecting a stable result is unrealistic.
④ I think it’s a very basic question, but what does FTINY mean?
It’s defined as (1e-6) in common/fvect.h, and is used throughout Radiance as a small, non-zero number to compare near-zero values to. That way, setting -aa 1e-7 is the same as -aa 0. There are lots of places where this shows up, mostly to avoid floating-point inaccuracies from leading to wrong choices.
I understand that ad is the value that divides the hemisphere into several patches.
When you say that the minimum ad is corrected to 7, does that mean that the hemisphere is divided into 7 patches? Or is it 49?
I don’t really understand the significance of being squared.
Also, the ad that is often set in papers is x power of 2 (e.g. ad=32, 64…). So I thought I had to do that, but it is not true, is it?
So it doesn’t matter if the value of ad is 7, 9, 13, or 20.
The “n” variable is used to store one of two dimensions, so total samples is n*n. You’ll note that n is initially set to the square root of the -ad settings (times a weight coefficient) at line 264.
You can set the -ad value to whatever you like, but if you set it to something less than 49 and the -aa setting is > 0, then it will be the same as setting -ad 49.
I hope this is clear enough. Why does it matter so much in your case?
Thank you for your answer. I understand now.
I wanted to theoretically clarify the relationship between the calculation parameters of Radiance and the calculation accuracy, but when the values of the parameters were scarce, I was having trouble explaining it.
I do not believe that I will actually be simulating with such values.
I read in the manual that the number of ambient super-samplings specified by [-as] should be 1/2 or 1/4 of [-ad], why is that?
Also, can I assume that the number specified in [-as] is the number of rays that will be added?
(If I set [-as]=512, will 512 rays be added? Or is it a maximum of 512? Or some other idea?)
You can set the -as to whatever you like, and it will send that number of additional rays to resolve variance discovered in the initial set of sample divisions. However, it’s generally a bad idea to set -as much larger than -ad, because it actually makes the convergence worse than using those rays in the initial sample set. So, the 1/2 or 1/4 recommendation is just that, a recommendation based on what seems to work best in most scenarios.
No, the reason the convergence gets worse is more subtle than that. If you set too few initial ambient divisions (-ad), you won’t do as good a job spotting the local variances you are trying to reduce with the ambient super-samples (-as). You will end up spending samples in the wrong places, and getting a less accurate result than you would if you had more divisions and fewer super-samples. Again, this is a general statement, and the variation in lighting in the scene along with scene complexity both have an influence.