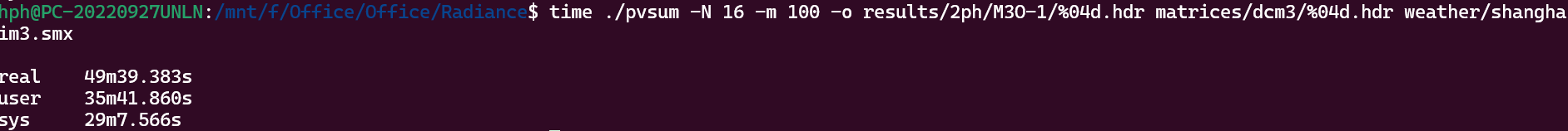I have implemented a highly optimized version of dctimestep, achieving a significant performance increase (an 8x to 34x speedup). The primary modifications are as follows:
Memory-Mapped I/O: The daylight coefficient HDR images were combined into a single binary file and accessed via memory mapping (lazy loading) to reduce I/O overhead.
Matrix Multiplication: The sum_images function was refactored to perform matrix multiplication, replacing the traditional sequential weighted accumulation of multiple images.
Hardware Acceleration & Parallelism: The matrix multiplication was heavily optimized using:
SIMD: Processes 8 pixels (24 floating-point values) simultaneously in a single CPU cycle, rather than one by one.
Multi-threading: Leverages OpenMP to distribute computations across multiple CPU cores.
Zero-Skipping (Sparsity Optimization): Bypasses calculations for completely black (zero-value) pixels, drastically reducing processing time for sparse images.
Sun Matrix Fallback: If the weather data is a sun matrix, the program dynamically falls back to the original method of weighted image accumulation.
The complied binary files and source files was uploaded here.(dctimestep files - Google Drive).
When compiling the files with gcc, the compiler flags -mavx2, -mfma, and -fopenmp must be included. For example: gcc -O3 -mavx2 -mfma -fopenmp cmatrix.c cmbsdf.c dctimestep.c -I../../src/common -L../../build/src/lib -lrtrad -lm -o dctimestep
Great! I’d like to give it a try on MacOS, probably this week. I noticed that you must have worked from an older version of cmatrix.c, because there were a bunch of unrelated differences due to updates and changes I made over the past year or two.
If you have time at a later point, it would also be interesting to compare performance to the new pvsum command, which overlaps somewhat with dctimestep but adds some optimizations under Unix (not Windows). If I get this working under macOS, I will definitely be comparing the two.
I’ve synced my code with the latest updates (Link: dctimestep files - Google Drive).
I’m currently working on the performance comparison with pvsum and will share the results soon.
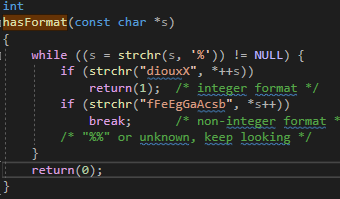
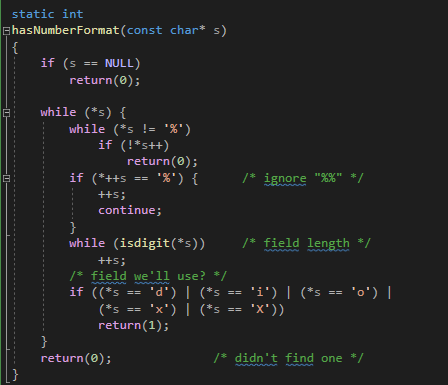
Additionally, I noticed that the hasFormat function cannot recognize formats like %04d, which causes an error (see Fig. 3). Therefore, I have replaced it with hasNumberFormat.
Oops – I had made a change just yesterday to the format detection routine and introduced a bug while attempting to fix another (more minor) one. I just checked in a fix to my fix – sorry about that.
Thanks for updating your code to the latest. I will see if I can run a comparison on my Mac mini m4 pro. If you can make your files available someplace, we could make sure it’s an apples-to-apples comparison. Otherwise, I’ll use something I have lying around.
I would like to include your code in the distribution, since it seems to be a huge performance improvement, but it may need to be an optional compile to avoid breaking the build on Apple Silicon and other incompatible systems.
Regarding your tests against pvsum, could you also try using the -m option set to your available RAM (in GBytes) and -N set to the number of physical cores? I’m wondering if the performance would be any better.
Hi Greg,
I have modifide the code to make it work on Apple computer and sent it to you through email. Additionally, I also have used -m option and -N set to the number of physical cores, below is the test results: